Technical Introduction
As can be seen in the accompanying editorial commentary for this edition, ncse is large and varied, containing well over 400,000 articles that originally appeared in roughly 3500 issues of six nineteenth-century periodicals. Published during a span of 84 years, materials within the corpus exist in numbered editions, and include supplements, wrapper materials and visual elements. A key challenge in creating a digital system for the management of such a body of material is to design and build appropriate and innovative tools to assist scholars in finding materials that support their research while challenging and enabling new and innovative approaches toward research.
In the past, notably on the Keyword project, the Centre for Computing in the Humanities (CCH) has investigated the use of computational linguistics techniques for the extraction of keywords from full-text content. The genesis of this work was the realization that a great deal of human effort and skill are required to add intellectual data such as keywords and abstracts to materials included in digital archives. 1 The benefits of doing so, however are clear; though full-text searching is useful in conducting 'known-item' searches, other kinds of metadata, including bibliographic description, keyword assignment, and the application of taxonomic structures to materials improve the precision of items returned (that is, their relevance to the research question at hand) and their recall, or the degree to which a search returns all relevant documents.
In a series of trials with collaborating institutions, the project used material in the corpus of the Forced Migration Online project, a digital library with a variety of on-line contemporary materials to demonstrate that the techniques of computational linguistics could be applied to full text content from digital libraries in order to extract 'meaningful keywords for a variety of purposes: browsing content, improving thesauri and metadata' 2
The technical components of ncse thus build on this earlier research to explore how the use of similar natural language processing techniques can be adapted and applied to enhance a scholarly edition, with the aim of addressing three primary research questions:
- How might a semantic 'view' be generated of items within the ncse corpus through a hybrid approach of manually and algorithmically assigned keywords?
- What kinds of end-user facilities could be produced using this data to aid the user in locating and selecting articles relevant to their research?
- How can this semantic environment best be integrated with end-user browsing and searching services provided within the Olive software?
Following is a brief overview of the technologies and processes used to create ncse. Interested readers may also wish to consult our list of Technical Acknowledgements.
ncse Facsimiles
The texts in ncse were scanned from microfilm by Olive Software and processed using their Viewpoint software.
ViewPoint comprises three main modules – XML Distiller, Olive XML Warehouse and the Olive ViewPoint Server 3 . The XML Distiller captures unstructured, multiple format document resources and transforms them into a unified, structured XML schema (PrXML). Content is fully indexed for searching and stored in the Olive XML warehouse file system. The ViewPoint Server provides dynamic access, viewing and search services. ViewPoint's XML-based search engine can search through the text of an entire document warehouse, including metadata, to retrieve components from multiple documents. The search engine displays search results based on the proprietary 'Relational Relevance Ranking' algorithm, allowing for retrieval of the relevant components from the specific documents that contain the search term, relative to neighboring components. Results are highlighted directly on the 'image'. A full catalogue record, produced by the research team, was also produced for each document using Olive software tools that included bibliographic and structural metadata. 4
-
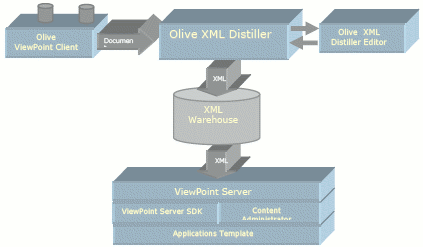
- Architectural diagram of Olive Software's Viewpoint.
Keyword Assignment
Keywords were assigned to materials by extracting the uncorrected OCR text of each article in the corpus from the Olive Viewpoint server, for storage within a MySQL token database.
Entities: Persons, Places and Institutions
Persons, locations and institution entities were extracted from the texts in the corpus using GATE, the General Architecture for Text Engineering. GATE allows for a number of text mining or language engineering tasks. It works on the basis of pipelines, in that the output of one sub-process is used ("piped into") as input for another sub-process.
The functions GATE provides can be accessed both via a graphical user interface and a JAVA API. The graphical user interface is ideal for testing parameters, and it also includes very useful facilities for evaluation, but is not well suited to bulk processing of large amounts of data. To process the large corpus of ncse texts as a batch, a Java program was written to interface directly with the GATE API.
Of the numerous functionalities that GATE offers, GATE's information extraction component ANNIE was used to extract names, locations and institutions from the corpus. After applying computational linguistics processes to the corpus including tokenization and part of speech tagging, ANNIE uses pre-determined rules, combined with gazetteer lookup to identify, mark up and extract the entities required. Rules are formulated using a mature, powerful grammar called JAPE.
Within the ncse, the JAPE rules were combined with a collection of gazetteer lists adapted for nineteenth-century texts, in order to produce results of a higher degree of accuracy. During the development of the overall keyword extraction process, the default gazetteer lists supplied with GATE were gradually augmented and improved. A very helpful addition to the collection of gazetteer lists were parts of the database of the Victorian Periodicals project that we were kindly allowed to use.
-
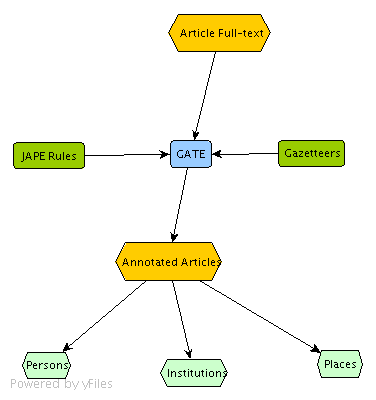
- Simplified model of the GATE entity extraction process.
Subject Descriptors
With the assistance of Paul Rayson of UCREL, a cross-departmental research centre at Lancaster University that specializes in computer-aided analysis of naturally occurring language, subject descriptors were automatically applied to the corpus. This work was performed using the UCREL Semantic Analysis System or USAS. USAS is a dictionary-based content analysis tool that automatically links words in running text to one or more semantic categories. 5
The USAS system is designed to undertake the automatic semantic analysis of present-day English texts (spoken and written), in a two-stage process:
- A part-of-speech tag is assigned to every lexical item or multi-word expression (MWE), using probabilistic Markov models of likely part-of-speech sequences (- 97% accuracy)
- Output is fed into SEMTAG, which assigns semantic field tags on the basis of pattern matching between the text and two computer dictionaries developed for use with the program, and then applies a set of disambiguation techniques intended to select the correct semantic tag on each item given its context (- 92% accuracy)
Within ncse, Dr. Rayson tailored USAS to process the entire the entire text of the corpus 6 . Reports were created for each article in the corpus over 300 characters 7 that included:
- a copy of the original file
- a semantic tag report with each lists of subject descriptors from the semantic tagset sorted in order of relevance
- a "names" report with lists of words of the semantic categories "personal names", "geographical names", and "other proper names" 8
-
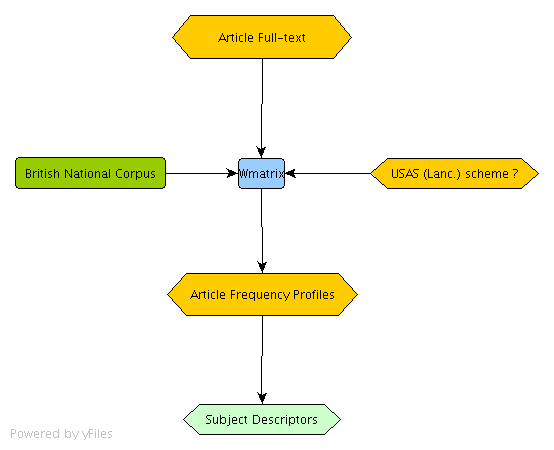
- Simplified model of the USAS subject descriptor process.
Image Descriptors
Images appearing within the corpus were manually catalogued by the editorial team within the Olive administrative interface using an adapted form of the Database of Mid-Victorian Illustration taxonomy, an organised system of iconographic terms tailor-made to describe Victorian visual art. To read more about this process, see the essay on Visual material within the editorial commentary.
Web Delivery Framework
To create the web delivery framework, extracted entities, semantic tags and image descriptors, along with the bibliographic metadata for each article, were aggregated according to their Olive system identifier. For each keyword type, a Python script was written to apply additional filters to the extracted data as a part of the aggregation process:
- Semantic Tags: Only those semantic tags assigned to a document which are calculated to have a 95% percentile significance level were included in the exported data. Any semantic tags belonging to the Z class were also removed.
- Person, Place, Institution Entities: Entities consisting entirely of non-alphanumeric characters as a result of incorrect OCR recognition were filtered out the of keyword framework, while such characters appearing within words were replaced by the underscore character ( _ ). Any entity that is a single character was also filtered.
- Image Keywords: All image keywords, having been human-assigned, were included in the keyword framework.
After filtering was complete, the Python script included items output for the web framework if: keywords exist in any form (semantic tags, persons, places, institutions or images), and meaningful bibliographic metadata (in particular, an item title) could be extracted from Olive repository.
-
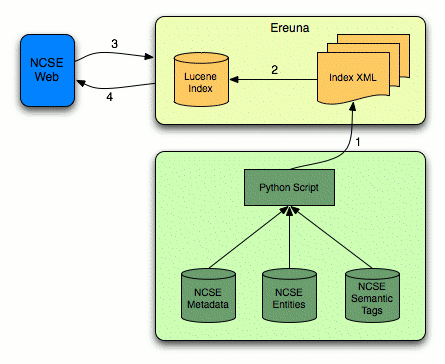
- Architectural diagram of CCH NCSE web framework.
Finally, the Python script created XML files for each file, optimised for use with Ereuna, a search framework, based on Apache Lucene, built with the purpose to speed the development of search facilities for web applications. This language independent framework can be used with a wide range of source materials (XML and non-XML bases), requiring little need for specific programming knowledge of the underlying Lucene architecture.
Within ncse, Ereuna works in the following way:
- First , the XML documents created by the Python aggregator are processed by Apache Lucene to create a searchable index;
- An Apache Cocoon web framework uses the index to execute searches and return search results (arrow 4 in the figure).
The web delivery framework thus comprises two interrelated components: the Olive produced facsimile repository which allows for full-text searching and browsing, and a rich keyword repository, in which users can browse for and search articles according to the ways in which they have been semantically identified.
Conclusions and Future Directions
Within the ncse project, the focus was on nineteenth-century language, an area for which specialized USAS thesauri do not yet exist, and GATE gazetteers must be crafted. In addition, the source text for the keyword generation work was uncorrected OCR. Therefore, while early results of this work are quite promising, the keyword index cannot yet boast of high precision or recall when compared to the full-text results generated in the Olive facsimile repository.
However, the work performed to-date for the ncse has allowed the CCH to explore the develoment of a full-featured bibliographic system developed using data mining techniques, and early anecdotal feedback suggests that the semantic 'view' metaphor used in constructing the beta website helps the user to find relevant documents, particularly for searches that include subject descriptors. Furthermore, early feedback suggests that the system invites the scholar to engage with the material in new ways.
In conclusion, the work of the ncse is perhaps best termed "at the end of the beginning". Planned enhancements include:
- Additional refinements to the facsimile repository user interface,
- Refinements to the keyword extraction processes, to improve reliability and relevance of terms returned,
- Development of 'user tools' for text mining and network analysis,
- Inclusion within the keyword repository of additional materials from the corpus, and
- Improved integration between the keyword and facsimile repositories.
Footnotes
- 1.
- Marilyn Deegan, Harold Short, Dawn Archer, Paul Baker, Tony McEnery, Paul Rayson (2004) Computational Linguistics Meets Metadata, or the Automatic Extraction of Key Words from Full Text Content. RLG Diginews, Vol. 8, No. 2. ISSN 1093-5371. Back to context...
- 2.
- For the full report of the outcomes of this work, read: http://www.keyword.kcl.ac.uk/redist/pdf/mellon.pdf Back to context...
- 3.
- To learn more about Olive Software, read: http://www.olivesoftware.com Back to context...
- 4.
- To learn more about the processes used in identifying and applying metadata to items, read Metadata in the editorial commentary. Back to context...
- 5.
- For an introduction to USAS, see: http://www.comp.lancs.ac.uk/computing/users/paul/publications/tokyo2002/ Back to context...
- 6.
- The text used for this work was taken from a 17 January 2008 "snapshot" of the corpus. Back to context...
- 7.
- This word threshold was selected as in articles shorter than 300 characters there is not enough context to enable the semtag-process to extract meaningful data. Back to context...
- 8.
- This separate names report was created to use in comparison with the GATE entity output. Back to context...